#pyspark
Read more stories on Hashnode
Articles with this tag
Slowly Changing Dimensions (SCDs) are a vital concept in data warehousing, particularly in managing data that changes over time. As the entities...
1. Broadcast Join When dealing with the challenge of joining a larger DataFrame with a smaller one in PySpark, the conventional Spark join operation...
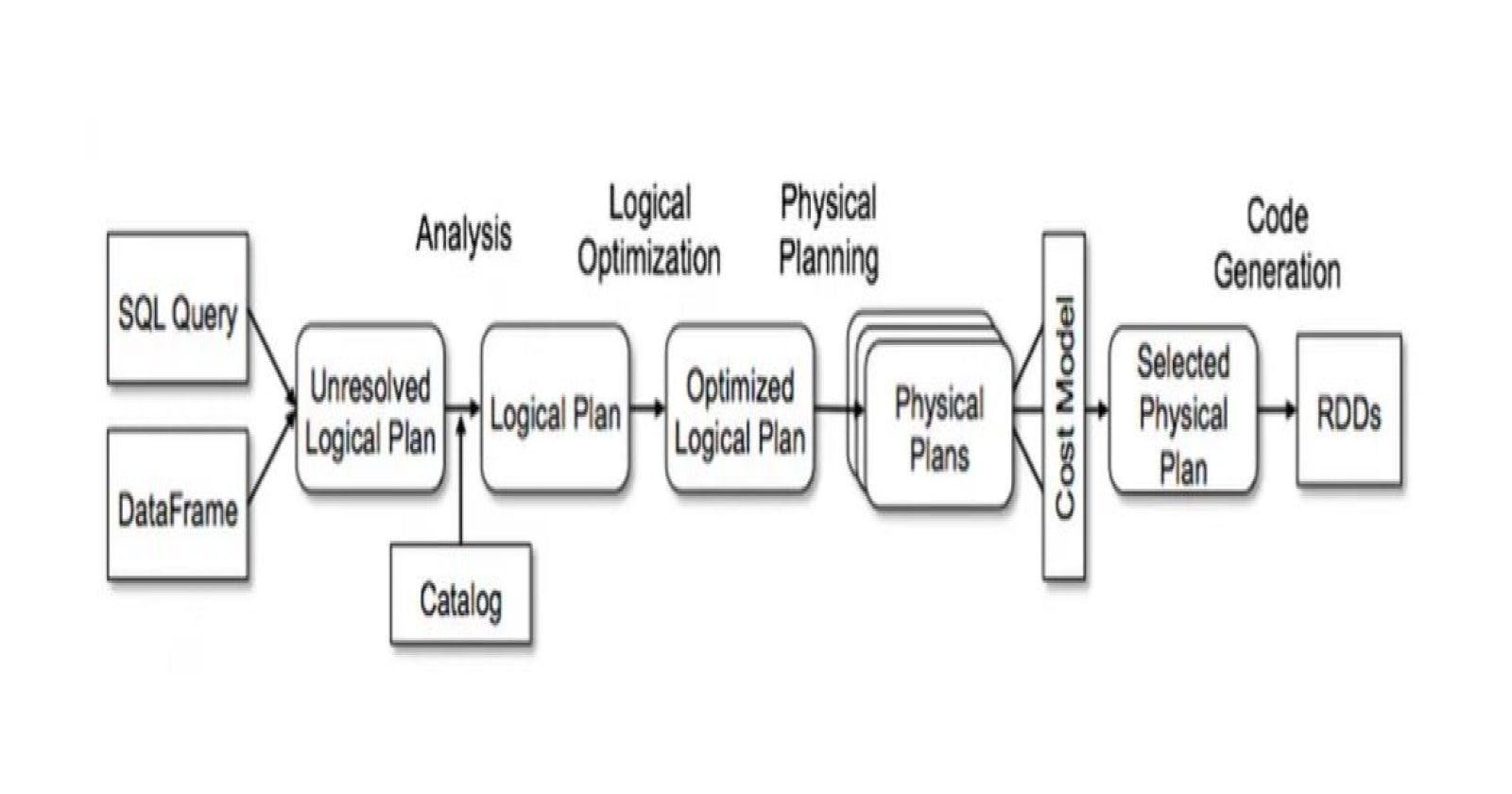
Spark's Execution Plan is a series of operations carried out to translate SQL statements into a set of logical and physical operations. In short, it...
Incremental data load refers to the process of integrating new or updated data into an existing dataset or database without the need to reload all the...
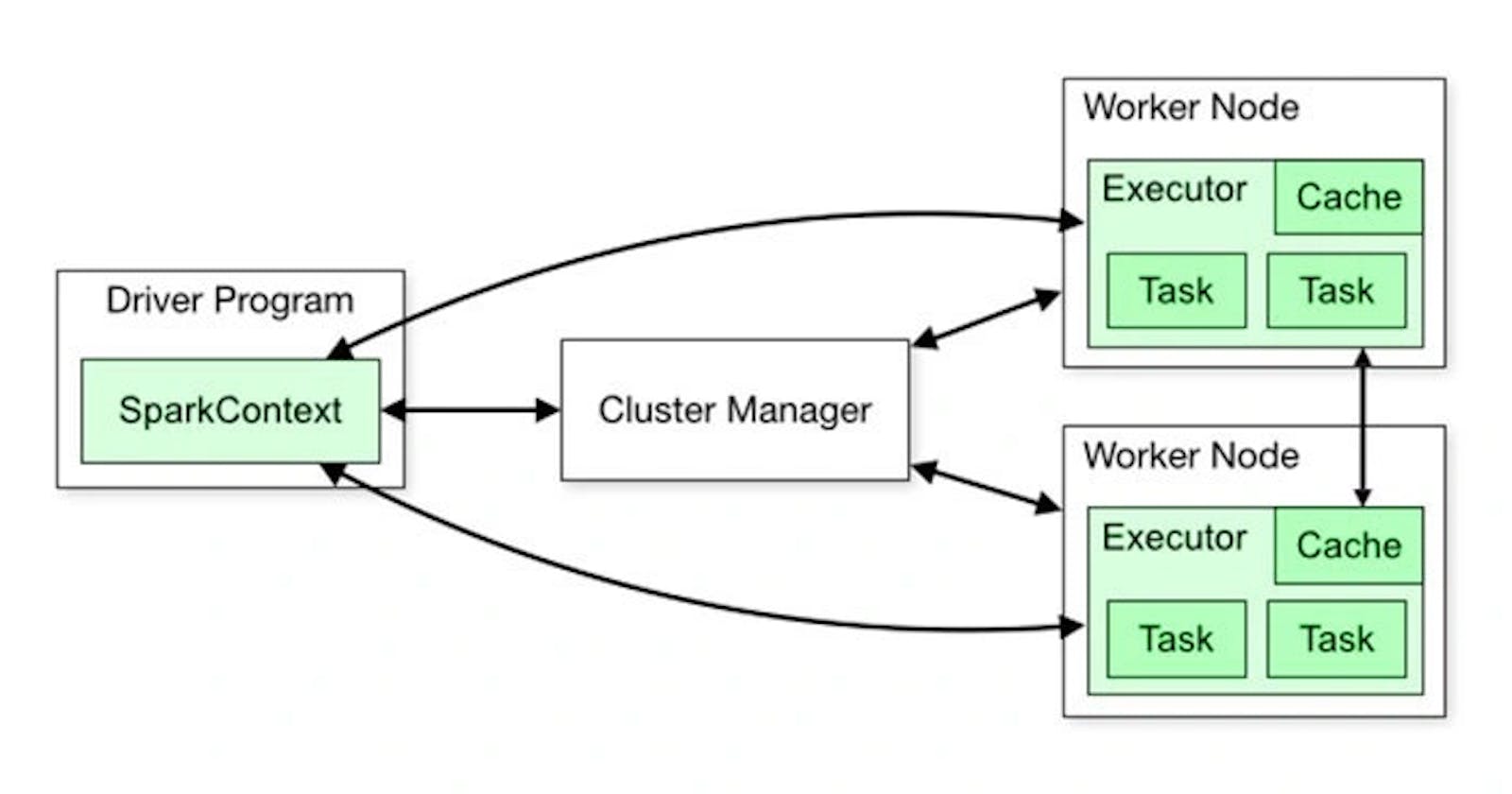
Apache Spark is an open-source distributed computing system that provides an efficient and fast data processing framework for big data and analytics....
Apache Spark stands out as one of the most widely adopted cluster computing frameworks for efficiently processing large volumes of complex data. It...