PySpark Job Optimization Techniques (Part - II )


1. Broadcast Join
When dealing with the challenge of joining a larger DataFrame with a smaller one in PySpark, the conventional Spark join operation can become resource-intensive in terms of both memory and time. This is particularly evident when the larger DataFrame is distributed across multiple nodes within a cluster. In such cases, bringing the data together on the same node becomes a crucial optimization.
PySpark addresses this issue through a strategy known as broadcasting, which significantly enhances the efficiency of join operations. The key principle involves broadcasting the smaller DataFrame to all executors, allowing each executor to retain a local copy of this DataFrame in memory.
For successful execution, the combined memory footprint of both the Driver and Executor must be sufficient to accommodate the smaller DataFrame. If this memory requirement is not met, out-of-memory errors can occur, hindering the performance gains achieved through broadcasting.
from pyspark.sql.functions import broadcast
df_large_file = spark.read.csv("/school/names.csv", inferSchema=True, header=True)
df_small_file = spark.read.csv("/school/marks.csv", inferSchema=True, header=True)
df_large_file.join(broadcast(df_small_file),
df_small_file.department_id == df_large_file.department_id
).explain()
2. Avoid Data Shuffling and Use ReduceByKey instead of GroupByKey
Shuffling represents a resource-intensive operation in Spark jobs, demanding significant time and memory resources. Its impact on performance is considerable, making it imperative to proactively minimize the occurrence of shuffles.
Let's leverage Spark's capability to set the number of partitions for shuffle operations.
spark.conf.set("spark.sql.shuffle.partitions",100)
ReduceByKey() vs GroupByKey()
ReduceByKey internally reduces the same key value and then shuffles the data but groupByKey shuffles data and then they try reducing it.
Example GroupByKey:-
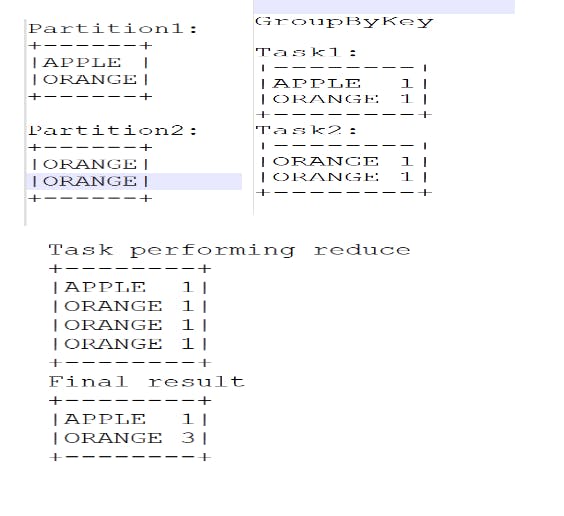
Example ReduceByKey() -

words = ["Alice", "Beta", "Cat", "Don", "Elly", "Fairy"]
wordPairsRDD = spark.sparkContext.parallelize(words).map(lambda word : (word, 1))
wordCountsWithReduce = wordPairsRDD.reduceByKey(lambda x,y: x+y).collect()
wordCountsWithGroup = wordPairsRDD.groupByKey().map(lambda x:(x[0], len(x[1]))).collect()