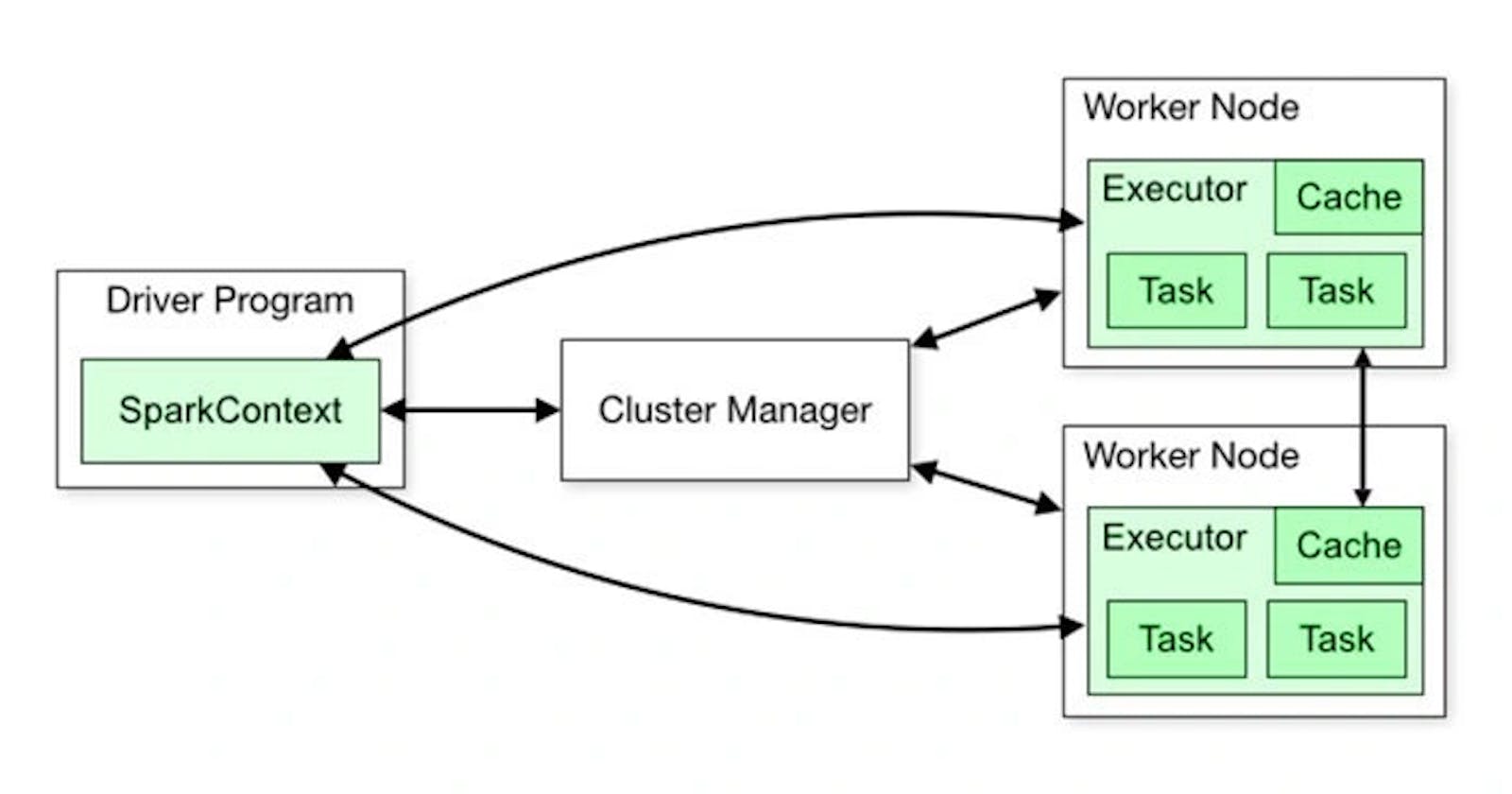


Apache Spark is an open-source distributed computing system that provides an efficient and fast data processing framework for big data and analytics. Its architecture is designed to handle various data processing tasks and supports real-time processing, machine learning, graph processing, and batch processing.
Spark follows a master-slave architecture, where there is a driver node and multiple worker nodes. Each worker node contains executors, and within each executor, there are tasks.
PermalinkCluster Manager
- Spark can run on various cluster managers like Apache Mesos, Hadoop YARN, or its built-in standalone cluster manager. These managers are responsible for resource allocation and scheduling tasks across the cluster nodes.
PermalinkDriver Program
- The driver program is the entry point of any Spark functionality. It contains the main function and creates a SparkContext, which is the core of any Spark application. The driver program defines the operations and transformations to be performed on the data.
PermalinkSparkContext
- SparkContext is the entry point for any Spark functionality. It coordinates the resources and orchestrates the execution of tasks on the cluster. It communicates with the cluster manager to acquire resources and execute tasks.
PermalinkWorker Nodes
- Worker nodes are the machines (physical or virtual) in the cluster where Spark tasks are executed. Each node runs an executor process that manages tasks and data partitions.
PermalinkExecutors
- Executors are processes running on worker nodes in the cluster. They are responsible for executing tasks and storing data in memory or on disk. Executors are launched by the cluster manager and communicate with the driver program and SparkContext.
PermalinkWorking on Spark Application
The driver program initiates the main application and establishes SparkContext, providing essential functionalities. It comprises components like DAG Scheduler, Task Scheduler, Backend Scheduler, and Block Manager, which translate user code into executed cluster jobs.
The Execution plan / DAG ( Directed Acyclic Graph is created while Transformations) - on submit code
DAG Scheduler is called.
Stages are created.
Task Scheduler is called.
Tasks are picked up.
Cluster Manager Negotiates with executor for resources.
Allocation of tasks to the executor and register with the Driver.
Read/Write/Process the task.
Executor reports back tasks success or failure state and results to Driver.
The cluster Manager deallocates the resources.
We will learn more about the process in detail in the next article related to the Spark Execution Plan.