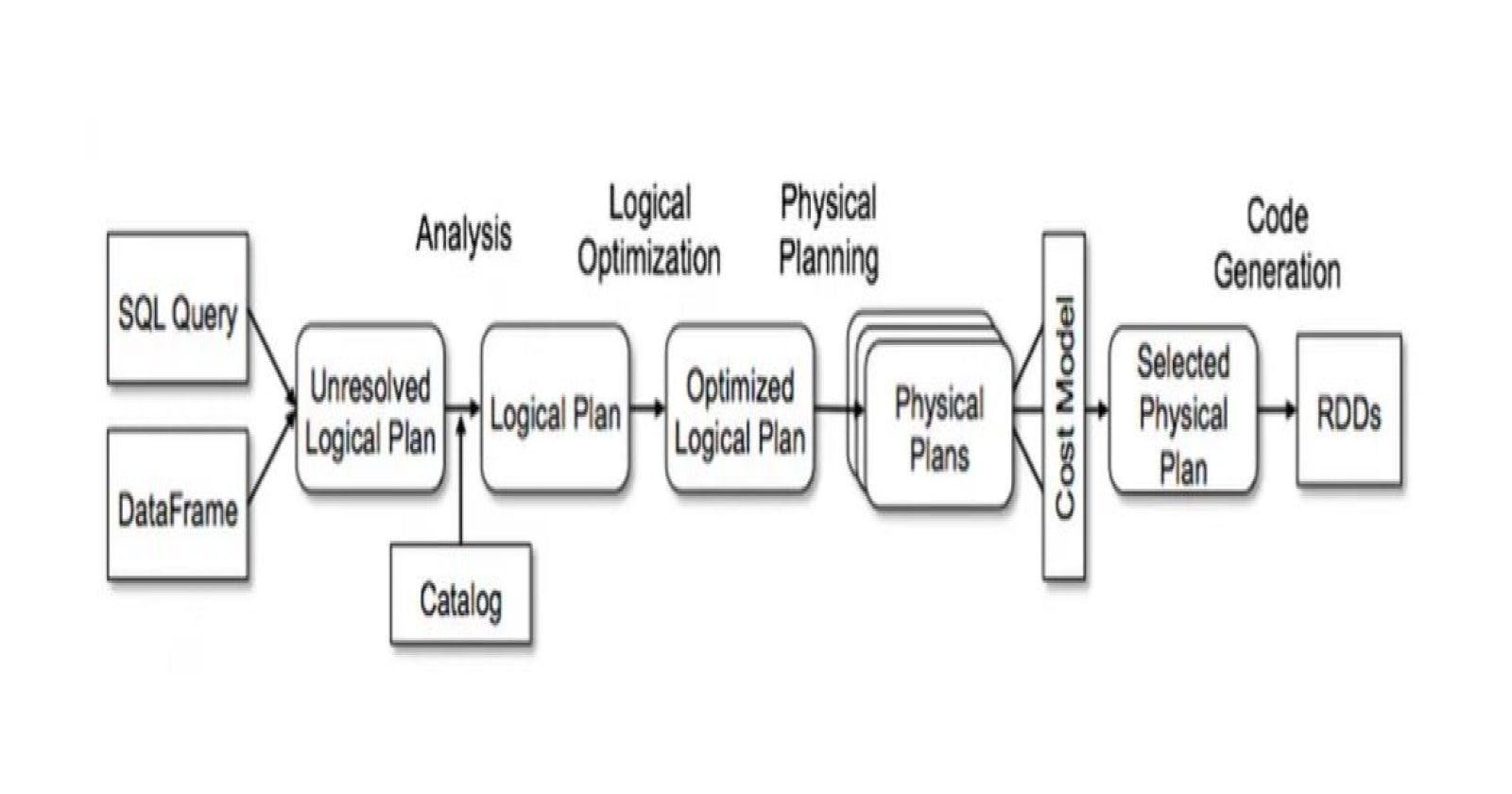


Spark's Execution Plan is a series of operations carried out to translate SQL statements into a set of logical and physical operations.
In short, it represents a sequence of operations executed from the SQL statement to the Directed Acyclic Graph (DAG) sent to Spark Executors.
The DAG is generated by the DAG scheduler. This graph consists of vertices and edges representing RDDs and the operations (transformations and actions) performed on RDDs.
Spark provides an EXPLAIN() API to look at the Spark execution plan for your Spark SQL query, DataFrame, and Dataset.
Apache spark uses Catalyst optimizer that discovers the most efficient execution plan for the operations.
data1 = [(1, "Java", "20000"),
(2, "c", "10000"),
(3, "C++", "30000")]
df1 = spark.createDataFrame(data1).toDF("id","language","tution_fees")
df1.createOrReplaceTempView("languages")
data2 = [("1", "studentA"), ("1", "studentB"),
("2", "studentA"), ("3", "studentC")]
df2= spark.createDataFrame(data2).toDF("language_id","studentName")
df2.createOrReplaceTempView("students")
df =spark.sql("""SELECT students.studentName, SUM(students.language_id) as c
FROM students
INNER JOIN languages
ON students.language_id= languages.id
WHERE students.studentName ='studentA'
group by students.studentName""")
The execution flow is like this:-
Unresolved logical plan
In this step, Spark generates a blank Logical Plan without validating column names, table names, etc. The plan only checks syntactic fields.
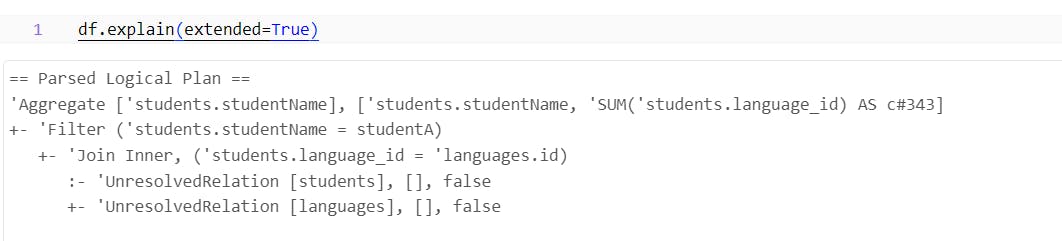
The output from the Parsed Logical Plan validates all aspects and constructs the initial version of the logical plan, establishing the execution flow (Aggregate, Filter, and Inner Join).
However, it encounters difficulty validating the join relationship between the 'students' and 'languages' tables, leading to the relation operation being marked as UnresolvedRelation."
Resolved Logical Plan
This plan resolves everything by accessing the Catalog, i.e., the internal Spark structure.
The 'Analyzer' helps us to resolve and verify the semantics, column names, and table names by cross-checking with the Catalog. The analyzer can reject the plan if it is unable to resolve them.
Dataframes/Datasets start performing the analysis without executing any action, which is why they follow semi-lazy evaluation.
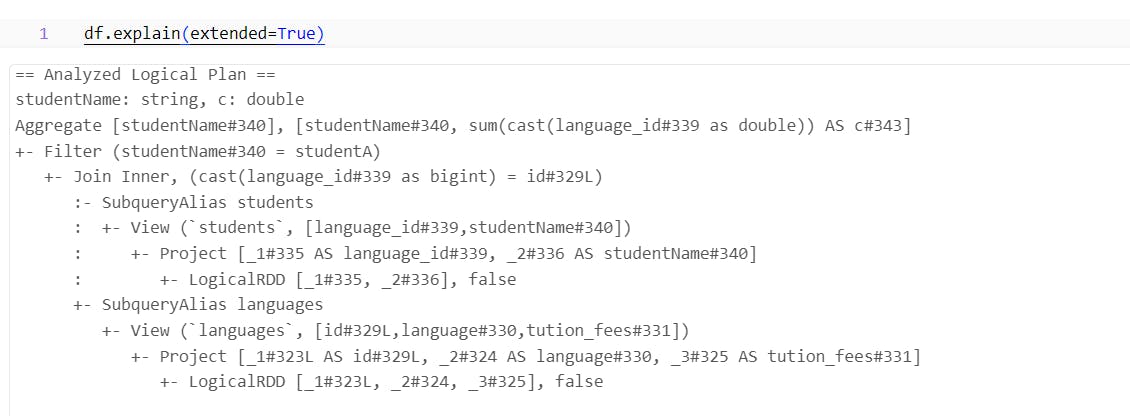
You can observe that the Join Relation operation between students and languages, which were previously marked as UnresolvedRelation, is now resolved. It has returned a SubqueryAlias operation from the spark_catalog, which has determined the Join relationship.
Optimized Logical plan
"In this process, the Catalyst optimizer attempts to optimize the plan by applying a series of rules. It determines the order of query execution to enhance performance, especially in situations involving multiple joins. The optimizer reviews all the tasks performed within a single stage.
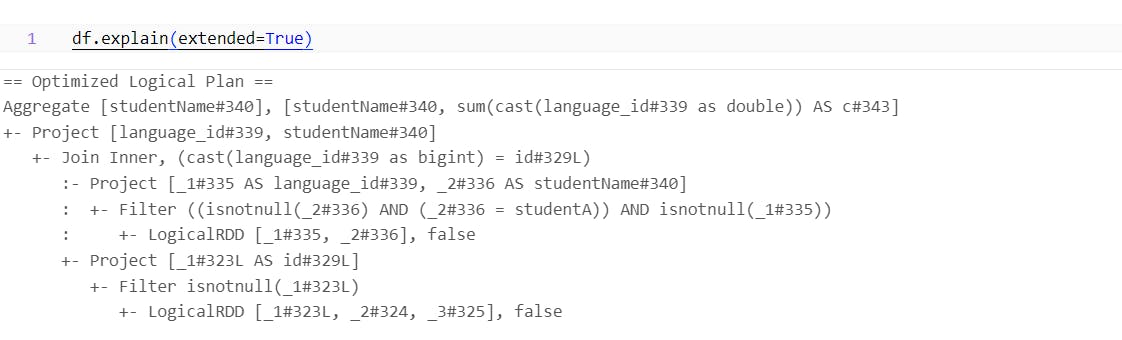
We can observe that the operations have been reordered; the WHERE clause is now directly applied to the student view, creating a new Student object and thereby reducing the volume of data being processed by the join.
Physical Plan
A plan outlining the physical execution on the cluster will be generated. The Spark Catalyst optimizer creates multiple physical plans and compares them using the Cost Model, considering factors such as execution time and resource consumption. The best optimal plan is then selected as the Final Physical Plan, which runs on the executors.

Thanks !!