


A Delta Lake is not different from a Parquet file with a robust versioning system. It utilizes transaction logs stored in JSON files to maintain a comprehensive change history for the file. This allows us to not only access previous versions but also to revert changes if needed.
Delta Lake operates on ACID properties, ensuring the handling of inconsistent readings and job failures. While it doesn't accommodate incorrect schemas, it does support schema evolution. Additionally, Delta Lake offers CRUD (Create, Read, Update, Delete) capabilities that are not available in raw files. It is designed to work with cloud data lakes and provides support for batch and streaming data workloads.
Delta Lake Components
Delta lake is made up of 3 components: -
Delta Table: This table functions as a transactional repository, storing data in a columnar format optimized for large-scale data processing. Its unique feature lies in supporting schema evolution, ensuring data consistency across all versions.
Delta Logs: The Delta Log comprises transactional records that meticulously document all operations performed on the table. Its primary responsibilities include upholding durability and consistency, offering versioning capabilities, and facilitating rollbacks as needed.
Storage Layer: This layer serves as the repository for data within Delta Lake. In the context of Azure, it utilizes Azure Data Lake Storage, while in the case of AWS, it relies on Amazon S3. The storage layer not only ensures durability and scalability for the data but also empowers users to store and process extensive datasets without delving into the intricacies of the underlying infrastructure.
Deep Dive into Working Of Transaction logs
The transaction log serves as the foundational mechanism enabling Delta Lake to provide atomicity assurance. By exclusively documenting transactions that are executed seamlessly and in their entirety, and by utilizing this record as the definitive source of truth, the Delta Lake transaction log empowers users to comprehend their data and assures fundamental trustworthiness—even at the scale of petabytes.
Upon the creation of a Delta Lake table by a user, the transaction log for that table is automatically generated within the _delta_log subdirectory.
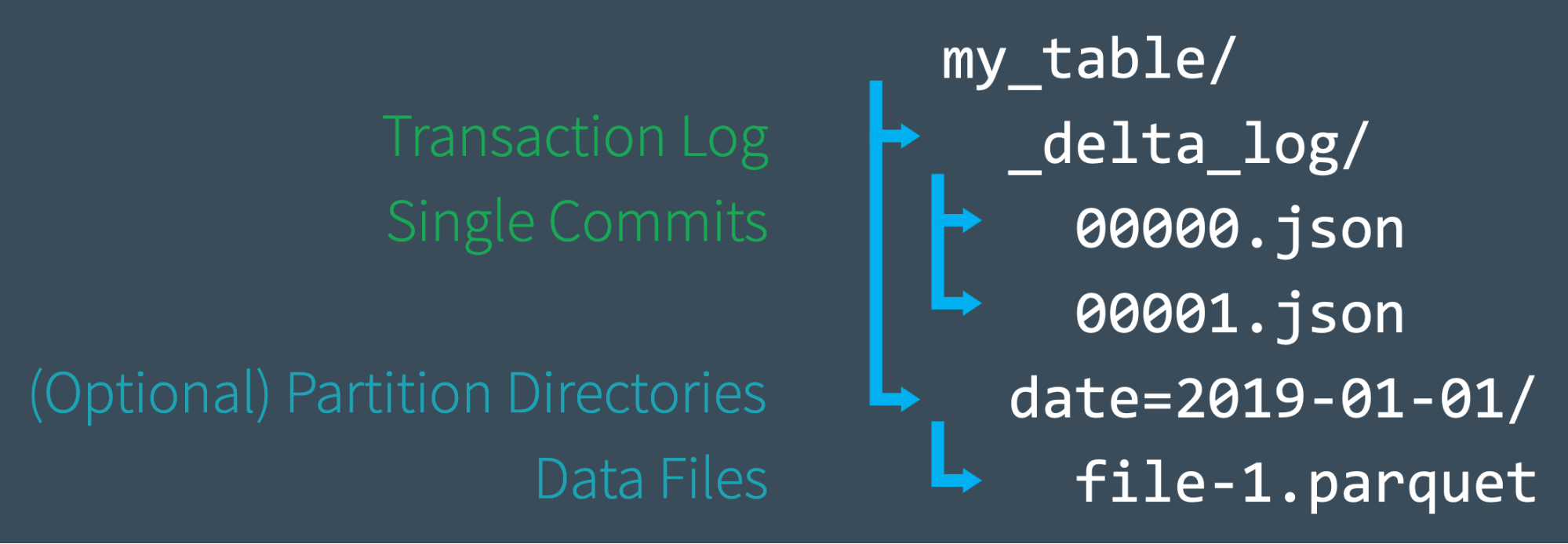
Each commit is documented as a JSON file, commencing with 000000.json. Subsequent commits are sequentially recorded as 000001.json, 000002.json, and so forth. Within each commit, multiple actions are encapsulated.
To elucidate the concept of commits and actions, refer to the diagram below:

Now we have 2 actions in 1st commit with JSON file 000000.json . We add additional records to our table from the data files 1.parquet and 2.parquet. Now we changed our mind and want to remove previously added files and add 3.parquet . So 3 actions performed in 2nd commit with JSON file 000001.json .
Checkpoint Files
Once we made many commits, Delta lake saves one checkpoint file in parquet file format in same sub directory _delta_log to maintain good read performance. By default it gets created by 10 JSON files.
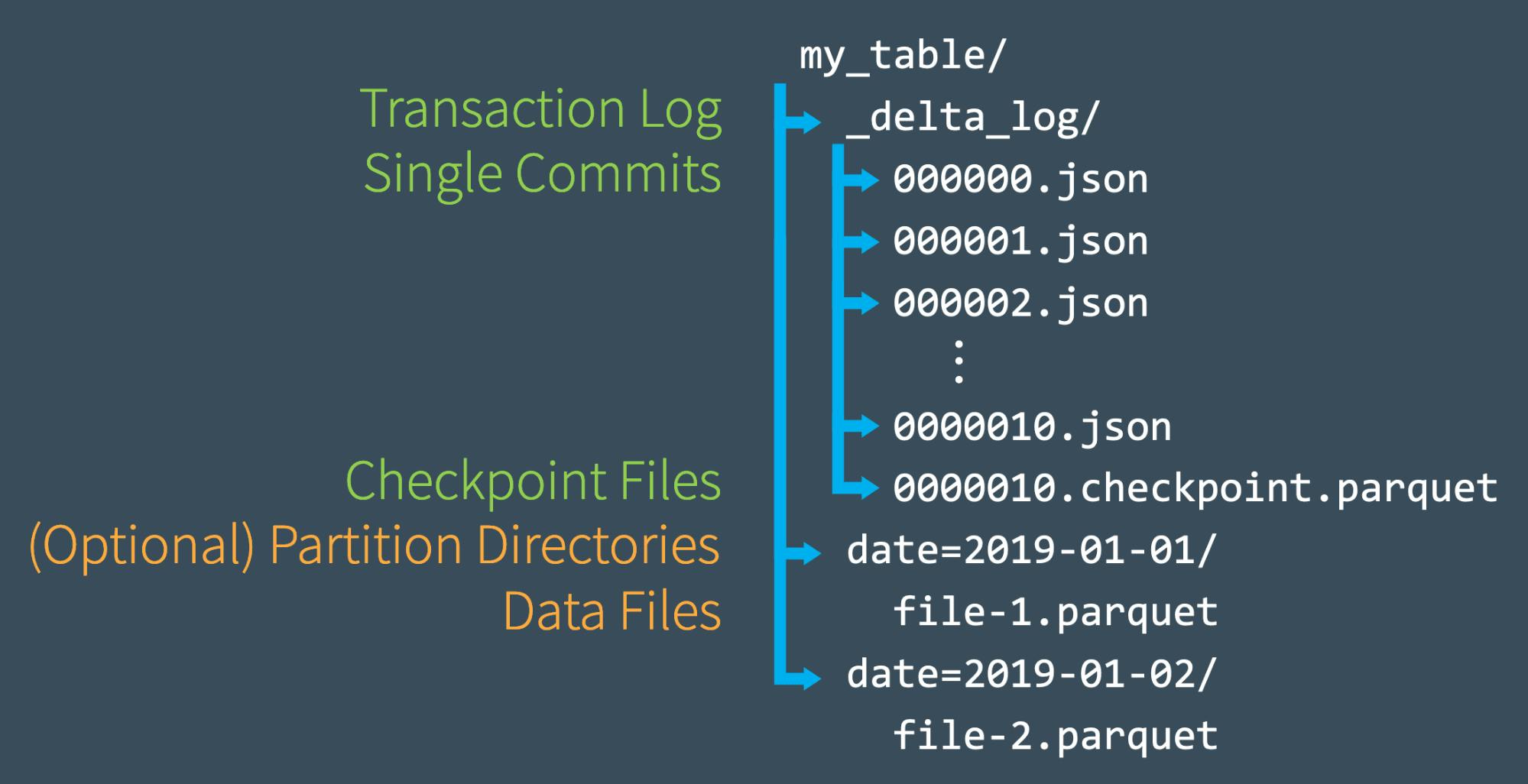
This offers Spark reader a sort of “shortcut” to fully reproducing a table’s state that allows Spark to avoid reprocessing what could be thousands of tiny, inefficient JSON files. Rather than processing all of the intermediate JSON files, Spark can skip ahead to the most recent checkpoint file.
Thanks !!