Traditional data formats like CSV or JSON are human-readable formats and as the data is growing it is very difficult to store such unstructured or semi-structured data in these formats.
If we can store also it in JSON, the retrieval of data is not easy. Data is in complex data types and these formats don't support the evolution of schema.
What characteristics ideal file format should have?
Read fast
Write fast
Splittable i.e. multiple parts of a file are running parallel
Supports Schema evolution
Supports compression using various compression codecs (Snappy, LZO)
Well, the above-mentioned characteristics are ideal, we can't get all the things into one format. If our priority is one then we may have to compromise with another.
For example - If we want to read the file fast we may have to compromise with the writing in a file. How this is possible we are discussing it below.
So there are 3 kinds of Data storage:-
Row Based
Column Based / Columnar
Hybrid Based
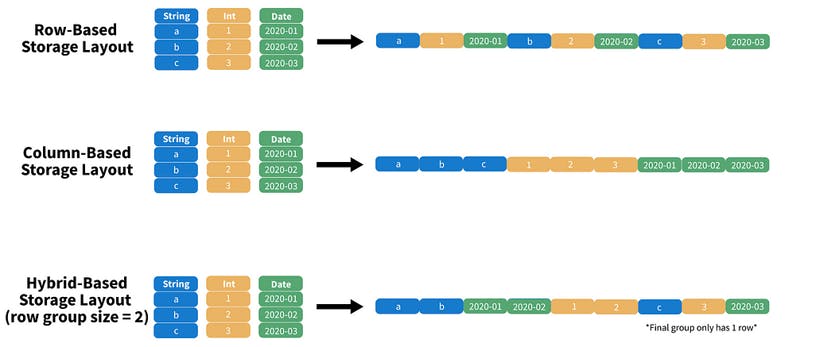
Row Based
All data associated with a specific record is stored adjacently. In other words, the data of each row is arranged such that the last column of a row is stored next to the first column entry of the succeeding data row.
Columnar
The values of each table column (field) are stored next to each other. This means that items are grouped and stored next to one another.
Based on our use cases we have to select the type of storage we want. If we want to read the data fast we can go with Column based as it is storing each column together of the same data type.
For writing faster or to change schema we should opt row based as it is easy to append the whole row together.
Types of formats
All the data format frameworks are platform dependent because they are created to support the organization platform best.
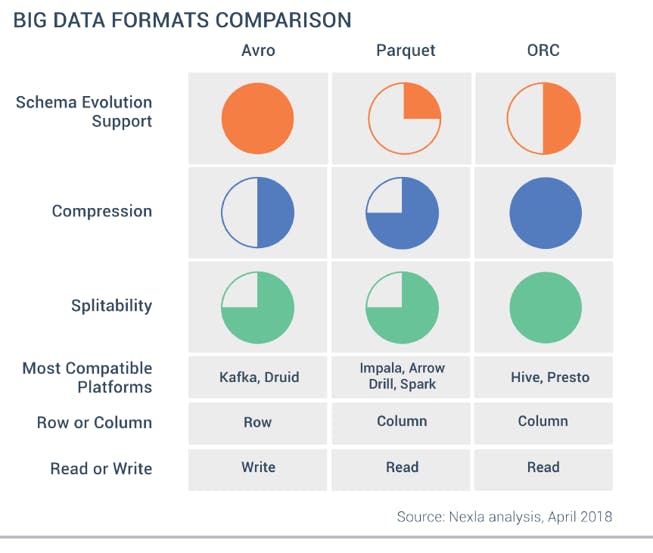
ORC - Optimized Row Columnar
designed for PIG, HIVE
Column Based
Read Fast - The file is divided into stripes with each stripe size 250 MB; the large stripe size is what enables efficient reads.
Schema evolution support - When a new column is added to an ORC file, the file's metadata is updated to include the new column and the data is written using the new schema. When reading the file, the ORC reader can automatically use the latest schema to provide a consistent view of the data. It allows more complex schema changes without having to rewrite the entire file.
Less intensive to support nested data types
Compression with the Snappy algorithm is better than parquet
Parquet
Columnar or sometimes behaves as a hybrid too
Designed for spark
No Schema Evolution support
Read Faster
Good compression
Can handle complex data structures - By supporting nested fields, repetition levels, and efficient encoding, Parquet enables the storage and processing of complex data types in an efficient and scalable manner.
Allows efficient querying of data
AVRO
Row Based
Write fast
Supports full schema evolution support
The Avro format stores data definitions (the schema) in JSON and is easily read and interpreted. The data within the file is stored in binary format, making it compact and space-efficient.
Splittable
Big Data Formats Comparisons